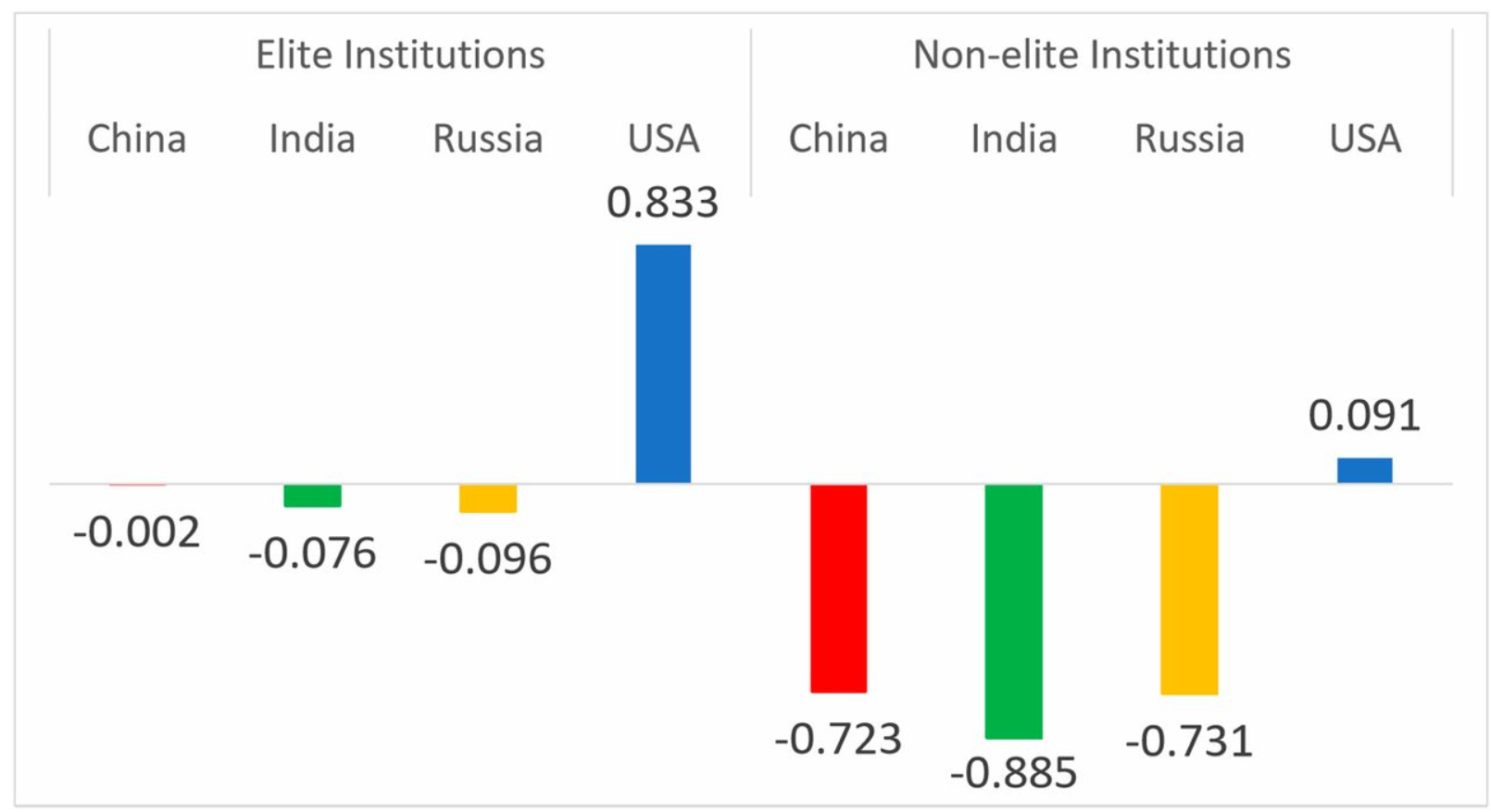
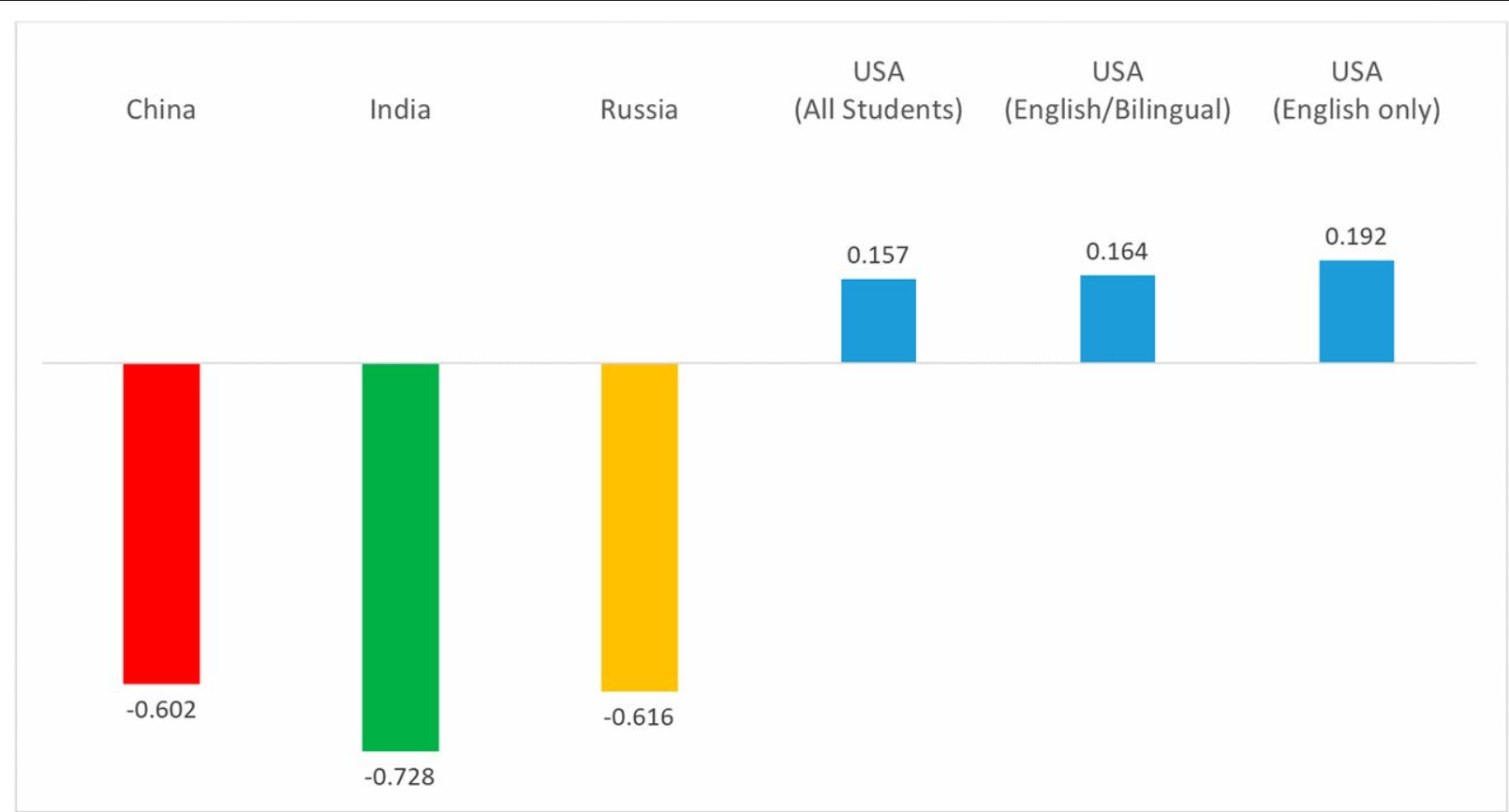
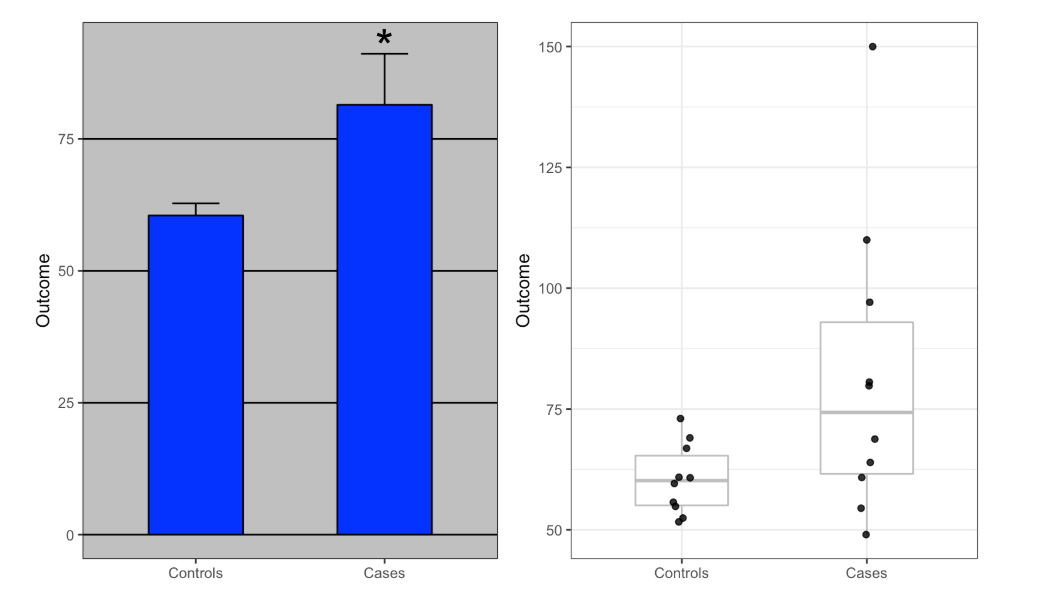
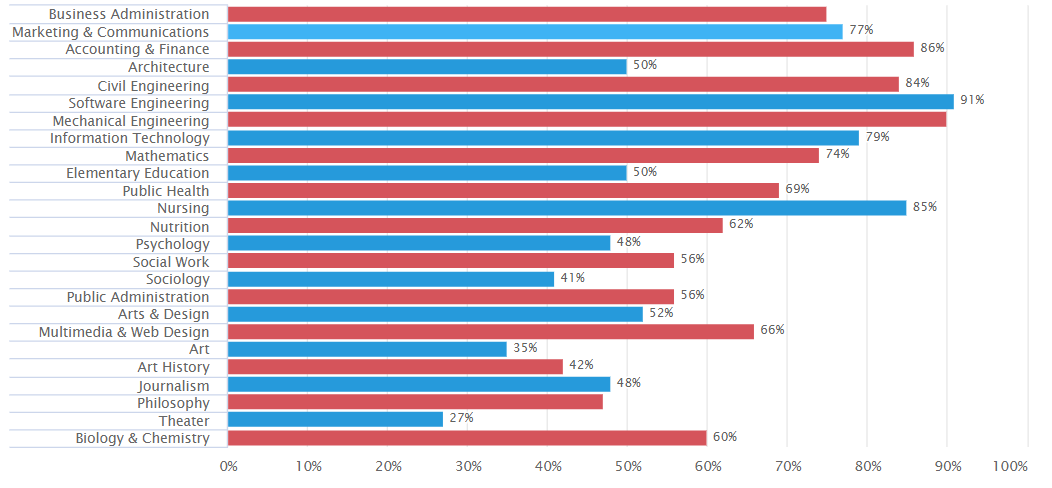
Towards the beginning of class, we read Homo Deus by Yuval Noah Harari. In his book, Harari describes the idea of data-ism and the idea that all data should be open and within the public domain. His argument for this centers around a data-oriented utility theory, saying that the gathering and publicizing of incredibly large data sets will allow the human race to evolve socially and technologically at an accelerated rate. Reading his book left me thinking about the vaste data collections that modern tech-giants have amassed. It seems to me that keeping the data you collect privatized is a huge economic advantage, especially with regards to your competitors. If you know your market better than anyone else (as a result of careful data collection through your service), you have a better chance of maintaining control in that market. However, some companies still choose to release more and more information about their data. This could be in response to social pressures in an increasingly data focused political environment. Regardless this line of thinking has brought be to ask, should companies release their data sets?
I read this article to get me started. The article talks about Netflix choosing to release more of its viewership data and is summarized as follows: Previously Netflix has been very secretive about their viewership data, only releasing tidbits at a time, if at all. In December 2018 they announced “that more than 45 million accounts watched its horror movie Bird Box within the first seven days of its release”. The article goes on to explain that Netflix will lean into being more transparent “quarter by quarter”, and argues that this transparency will be a good thing for Netflix, stating as evidence the fact that the company has faced considerable criticism for combining secrecy about its ratings with occasional self-aggrandizing claims.
The article seems hopeful that Netflix will release all of its data into the public domain, but skeptical that the release will not just be limited to a few select titles. While I think this piece makes some interesting points, I am not fully convinced that full data disclosure is the correct route for Netflix to follow, and I think the company likely agrees with me. It seems like Netflix is slowly releasing more data as a response to social pressures, perhaps in response to criticisms of their groundless viewership boasting. The reason they been secure and sensitive in their data handling thus far is that it is advantageous to horde and protect that information. Thinking about Harari’s argument, Data-ists would want the full data-sets released and within the public domain. But I would claim that the data has ownership by Netflix, and that they have no true obligation to provide it to anyone.
While this article does not answer my original question at all, it is helpful to explore its implications in light of that overall question. Do companies need to release their data? The articles author would likely take the position that transparency is more trustworthy and perhaps builds a more stable business model when appealing to consumers. I think the advantage of hoarding data is in strong contention to that point. I would tend to disagree with data-ists on the matter that the information should belong to everyone, because I think it should belong to the people who work so hard to collect it in the first place.